【特集】KDDIの大規模な年末年始の障害における根本原因と対策(後編1) ( 2013-01-25 23:30:00 )

KDDIの年末年始に発生した最大180万規模の大規模障害の根本原因と対策に関する特集後編は、障害の技術的背景を含めた詳細(後編1)と、取材時の質疑応答(後編2)に分けてレポートする。
今回の障害は、LTEデータ通信に関する障害と、au ID認証決済システム障害の2つに大別できる。(3GおよびWiMAXによるデータ通信および音声通話に関する障害は無かった。)
1. au 4G LTEデータ通信障害
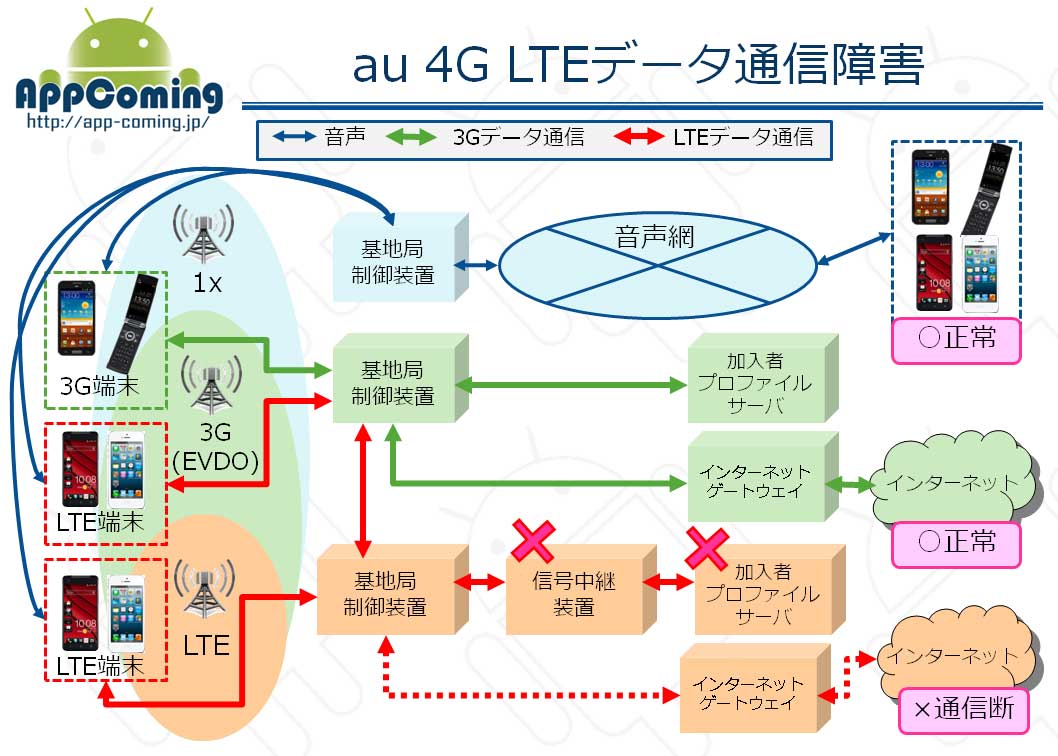
※3Gの構成で信号制御装置が含まれていないが、サーバが同機能を担っている。
LTEデータ通信障害は、『加入者プロファイルサーバ』と、『信号中継装置』の2つの機器が直接的な障害要因であった。
加入者プロファイルサーバは、利用回線の月間利用量7GB制限を超過しているかを判断するもので、ユーザ数が増加すればその分だけ処理能力が必要になる。
※年末時点の影響最大数180万との発表により、LTE加入契約数が180万を超えていることが明らかになったが、au 4G LTE対象機種がiPhone5のみで供給不足だった期間と、au 4G LTE対応のAndroid対象機種が発売開始となった11月2日以降、更に人気機種のHTC J butterfly発売開始の12月9日以降では、加入者数の増加ペースは異なるはずだが、60万/月程度のLTE契約増があることが推察される。
NTTドコモのLTEサービスXiの月間加入者数(2012年12月:1,284,000=TCA http://www.tca.or.jp/database/2012/12/ )を上回る事は無いが、新たなLTEサービスと考えれば、急速な増加ペースであることに間違いはない。
この認証システムは、日跨ぎの0時過ぎに認証が集中する仕組みではなく、セッションの都度に認証を行なっている事から、認証方式・タイミングによる過負荷発生ではなく、クライアント(LTE端末)からのアクセスによる過負荷発生である。
クライアントからのアクセス集中は、アプリケーションからのインターネットアクセス要求が自動的かつ同時に行われているということが原因と特定できているが、前編記載の通りKDDI以外のサードベンダーアプリによる自動アクセスによるものだ。(アプリケーション名はKDDIとして非公表)
アプリそのものが自動的にアクセスする理由としては、バックグラウンドでの定期的なバージョンアップ有無の確認や、ニュース・天気予報などのコンテンツの更新などがそれに該当するもので、アプリを起動している意識がなくても、アプリの権限によって自動的なインターネット接続が発生している。 このアプリによる自動アクセスが0時過ぎに集中することで23時台の7倍のアクセスが発生し、加入者プロファイルサーバが過負荷状態=バッファオーバーフローに陥った理由だ。
KDDIは、この加入者プロファイルサーバが0時台に高負荷状態になる事を11月には確認しており、加入者増加傾向も踏まえて12月上旬に前倒しでのサーバ増強を行なっているという。
しかし、12月31日0時過ぎに、加入者プロファイルサーバの過負荷によるバッファオーバーフローが発生し、LTEデータ通信ができない状態となった。
加入者プロファイルサーバは、通常時に0.1秒程度で処理がなされており、仮に過負荷状態になると信号中継装置からのリクエストを破棄する仕様になっているが、サーバ増強から1か月足らずでバッファオーバーフローが発生している。
信号制御装置は、加入者プロファイルサーバからのレスポンスを3秒まで待ち受ける仕様であったが、その結果を返す信号中継装置は2秒までしか待たないために、加入者プロファイルサーバが信号制御装置に3秒以内でレスポンスを返しても、信号中継装置では既にセッションが解放されており、認証プロセスは完了せず、クライアントからの新たな認証要求が再発生することになる。
信号中継装置の待受が上限2秒に対して、その後の処理がそれを超える3秒に設定する事は不整合であり、信号制御装置の待受上限設定を3秒から1.2秒に変更することで、この不整合を既に解消している。
信号中継装置<0.8秒以内>信号制御装置<1.2秒以内>加入者プロファイルサーバ
加入者プロファイルサーバのパフォーマンスは十分に確保しているという話があったが、処理能力が高ければ2秒以内に信号中継装置まで認証結果を返す事ができたであろうと想定されることから、サーバ増強に対する意識(サーバ処理能力の見積)が不十分、過負荷試験が不十分、過負荷状態の監視・管理体制が甘かったと考えられる。
負荷増加傾向・過負荷状態の発生が十分に想定されている状況であり(想定していなければ、設計・構築・運用に関わった者の慢心や無責任・無関心でしかない)、オーバースペックとまではいかずとも、加入者数の増加傾向も踏まえ、かつデイリーの0時台のリソース状況・処理速度などをモニタリングしていれば、事前の対策は可能だったと考えられるだけに、障害発生は未然に防げたはずだ。 もしも、処理速度などの数値情報をモニタリングできないということであれば、システムとしての不備ということになるだろう。
今回の対策としては、加入者プロファイルサーバを障害発生時の2倍の処理能力まで向上させる増強を行なっているが、加入者数の急速な増加や、コントロールできないサードベンダーアプリの自動アクセスによる発生という状況から、過負荷状況に至る可能性は否定できないが、信号制御装置が加入者プロファイルサーバに代わって応答する機能(代理応答機能)を追加したことで、クライアント(LTE端末)からの再認証要求は発生せず、リトライによる過負荷発生は防止できるようになったため、同様のトラブルは発生しなくなるはずだ。
加入者プロファイルは月間7GB超過回線の帯域制限を行うためのものということで、認証のタイミングがずれる事によるユーザの不利益は発生しないため、過負荷時に実認証を行わずに代理応答で制限のないアクセス認証を行うという改修措置は、適切であり妥当だと言える。
![]()
また、1月2日には、信号制御装置の障害アラーム発報時に、運用者が対処法を見極める事ができないまま機器のリセットに至った事で、利用中のクライアント(LTE端末)から再認証リクエストが一斉に発生し、過負荷状況に陥って、LTEデータ通信ができない状態となった。
信号制御装置は、障害の種類などによりアラームを発報するものとしないものがあり、今回は、アラームを発報する必要の無い「ログをコピーする処理」での障害で想定外のアラーム発報し、かつ、アラームが鳴り続けるという例外状態が発生している。
機器の障害アラームについては、アラームID・メッセージがあり、アラーム発生時に対応した手順書が用意されているが(1アラームにつき2手順平均)、ログのコピー処理はアラーム対象条件ではないにも関わらず発報したため、運用者は、その真の原因を見極める事ができなかった。
年末から続く大規模障害の影響で30分以内の障害解消という目標(プレッシャー)の中、過負荷が発生する時間帯でのアラーム発報に、運用担当者は、例外的な手順書もない事態に直面し、自己(チーム)単独判断ではなく、エスカレーションして上長との電話会議を行なっているが、正しい状況を伝えきれておらず、結果として『年末の障害と同様の措置を行なって良い』という状況判断がなされ、機器リセットを実施している。
年末の障害とは異なる点として、アラームが鳴り続けている状態であり、かつ、LTEデータ通信障害は一切発生していないにも関わらず、障害切り分けせず、原因不明のまま、機器をリセットするという行動をしている。
機器をリセットするリスク=再接続要求に伴う過負荷・輻輳状態になる事を考慮すれば、LTEデータ通信が正常に行われているかどうか(インターネットゲートウェイを通過するトラフィック量の増減)、認証サーバが正常に稼働しているかどうか(リソースの状態)などにより、最後の手段とも言える機器リセットは慌てて行なわないはずだ。
正常状態である事、あるいは障害状態である事を確認するなどの原因切り分けの手段を講ずるなり、想定される原因を理解・掌握して状況を整理できてさえいれば、上長への説明も異なっているであろう。 一方で、エスカレーションにより重要な判断をする上長は、情報が少ない中でも年末との相違に気付き、状況確認や切り分け手段についての指示を出す事が期待されるが、スキル・経験に長けていなければ、解決する手段に至る道筋が開けないということになるはずだ。
その結果として、年末の障害対策が完了していない段階での過負荷が発生し、元となる原因は違うにせよ、同様の認証エラー・リトライを繰り返し、LTEデータ通信が利用できなくなるという、年末と同じ結果をもたらしている。
これらを原因でまとめると、以下の通りだ。
- 処理能力の誤算
- 設定ミス・設計考慮不足
- アプリの自動更新による過負荷
- 手順書漏れ(例外処理含む)
- 確認する手段・能力の不足および判断ミス
- 設計または実装ミス(アラーム誤発報)
2. au ID認証決済システム障害
au ID認証決済システムは、毎月1日に『auかんたん決済』の利⽤限度額をクリアする月次処理による大規模なオンライン処理が発生し、DBシステムが高負荷な状況になるが、ピークに対する設備処理能力はしっかりと管理できており、11月にもDBサーバを増強したばかりとのことであった。
しかし、増設の際にメモリアロケート処理の設定(パラメータ設定の組み合わせ)に誤りがあり、累積的なメモリ断片化が発生し、メモリの解放・割当によるCPU高負荷・過負荷状況になり、同一のDBシステムを利用するau ID認証サーバの処理が正常にできない状態に陥り、原因が掌握できないまま、再び不安定な状況に陥るという障害が発生した。 また、本障害に関連すると思われるユーザからのクレーム・問い合わせは1,000件ほどだった。
DBシステムについて確認したところ、オープンソース系(非商用)データベースを利用して、3台のサーバをレプリケーションしているとの説明があり、1台のDBサーバを切り離しても残されたサーバのメモリ状況も同様で、症状解消には至らない。また、OSが自動的に書き換えてしまう設定も問題だったようだ。
これらを原因でまとめると、以下の通りだ。
- DBサーバの設定ミス(設計ミス、設定作業ミス、または設定漏れ)
- 設定・仕様のチェック機能不足
- システムリソース管理・チェック機能不足
- 過負荷を見越したDBサーバのサイジング
- 負荷試験方法(断片化の再現)・検査項目の不足
- メモリ断片化の考慮漏れ
- 構築ベンダーの経験値・ノウハウ(?)
- 商用DBではない事による運用面での弱さ(?)
使用しているデータベース・OSについては、記事掲載NGとなる恐れがあったので、あえて確認をしていないが、取材で得た情報と専門外ながら限られたデータベースシステムの知識から想定すると、au ID認証のDBシステムは、postgreSQLでpgpoolによるレプリケーション・負荷分散を行なっており、処理能力は十分なリソースを配備しながらも、メモリ空き領域の解放を行うVACUUMまたはautovacuum(自動解放を行う場合)の設定ミスにより、今回の過負荷状態を引き起こしたと推察した。
VACUUMまたはautovacuumを実行すると高負荷な状態になるが、これは、質疑応答中にも説明があった「PCのデフラグと同様にCPUが高負荷状態になる」メモリの断片化解消時の状態に一致している。
このVACUUM・autovacuumの実施が適切なタイミング、適切なリソース割当、プロセスボリューム設定で行われていれば、1回あたりの処理量は少なくなり、高負荷状態の時間や負荷レベルも抑制でき、サーバ増強直後に障害が無かった事からも、影響は無いか軽微だったと考えられるが、1月1日の障害が発生する直前の時点ででは、断片化が進み処理能力が低下している中でVACUUM・autovacuumが実施され、高負荷状態に陥り、au ID認証サーバ障害に至ったのではないかと想定している。
つまり、vacuumが頻繁に実施されていれば、累積的な、あるいは時間が経過した事による過負荷には発展していなかったはずで、それを解消する設定変更を行なっていると想定する。
※autovacuumの関連しそうな設定には、autovacuum_vacuum_cost_delay・autovacuum_vacuum_cost_limit ・autovacuum_vacuum_scale_factor・autovacuum_analyze_thresholdなどがあるが、専門外でもあり、その詳細を省略する。
※参照URL(PDF)
PostgreSQLのチューニング技法(PostgreSQLしくみ分科会)P14~18・P30~35
http://www.postgresql.jp/events/pgcon09j/doc/b2-3.pdf
※autovacuumの効果については、2005年と古いが日経BP ITproの記事中のグラフを参照するとわかりやすい
[PostgreSQLウォッチ]第19回 ベータ・リリースを間近に控えたPostgreSQL 8.1
http://itpro.nikkeibp.co.jp/members/ITPro/oss/20050722/165140/
--
![]()
関連記事
- 『KDDIは、年末年始に発生したau 4G LTE関連の障害について、取材依頼のあったメディアに対して実施した。』
http://app-coming.jp/364.html
- 【特集】KDDIの大規模な年末年始の障害における根本原因と対策(前編)
http://app-coming.jp/367.html
- 【特集】KDDIの大規模な年末年始の障害における根本原因と対策(後編1)
http://app-coming.jp/368.html
- 【特集】KDDIの大規模な年末年始の障害における根本原因と対策(後編2)
http://app-coming.jp/369.html

